
Tijdens het installeren van Microsoft SQL Server op een dev omgeving, struikelde ik bij het installeren van database mail over de e-mail instellingen. Bij uitgaande mail gebruikte ik de reguliere SSL poort (465) die bij de meeste providers binnen een mailprogramma zoals MS Outlook ook wordt gebruikt. Bij Microsoft SQL Server werkt dient STARTTLS, poort 587 bij de meeste providers, te worden gebruikt. Vergeet bij het instellen dan niet het vinkje “This server requires a secure connection (SSL)” aan te zetten.
Hoe eenvoudig data tussen twee SQL Server databases wordt gekopieerd
Het komt wel eens voor dat er data tussen twee SQL Server databases moet worden gekopieerd. Daar zijn legio mogelijkheden voor. In deze bijdrage behandel ik er drie:
- Via ‘Generate scripts…’
- Via ‘Import/Export data…’
- … en een combinatie van de twee bovenstaande opties
Take away:
- In de import/export data wizard gebruikt u de data source Microsoft OLE DB Driver for SQL Server (Download)
- De Microsoft OLE DB Provider for SQL Server en de SQL Server Native Client zijn vervallen; zie Microsoft Docs
- De import/export wizard houdt geen rekening met de tabel opties in de brontabel(len)
- De ‘Generate scripts…’ wizard is niet heel geschikt voor heel grote tabellen
- Voor grote tabellen kunt u gebruik maken van ‘Generate scripts…’ voor het aanmaken van de objecten en de import/export wizard voor het kopiëren van de data
Correct instellen van SQL Server tempdb (best-practice)
Nog zeer regelmatig kom ik SQL Servers tegen, waarbij de tempdb niet optimaal is ingericht. Af en toe bekruipt mij het gevoel dat de tempdb database het sluitstuk van een SQL Server installatie is. Aan die database administrators geef ik graag mee dat tempdb een essentiële bouwsteen van de SQL Server is, die de performance van SQL Server kunnen maken of breken.
Waar tempdb het meest voor wordt gebruikt
- frequent maken en verwijderen van tijdelijke tabellen
- tijdelijke objecten die bij CURSORS worden gebruikt
- tijdelijke objecten die in combinatie met ORDER BY worden gebruikt
- tijdelijke objecten die in combinatie met GROUP BY worden gebruikt
- tijdelijke objecten die verband houden met het samenvoegen van data uit meerdere tabellen (HASH PLANS)
Bovenstaande acties kunnen tot opstoppingen in de tempdb leiden en daarmee de doorlooptijd van query’s.
Hoe wordt tempdb het beste ingericht
- Verhoog het aantal data bestanden. Voor machines met minder dan 8 processoren: houd het aantal databestanden gelijk aan het aantal processoren; bij meer dan 8 processoren, gebruik om te beginnen 8 data bestanden. Mocht dat niet voldoende zijn om opstopping tegen te gaan, verhoog dan het aantal data bestanden met een veelvoud van vier totdat het probleem met opstoppingen is opgelost óf het aantal data bestanden gelijk is aan het aantal processoren. Het advies is, zeker wanneer er meer dan acht data bestanden voor tempdb nodig blijken, de opzet van de gebruikte query’s nog een keer na te lopen.
- Zorg ervoor dat de databestanden van de tempdb altijd even groot zijn.
- Het is beter om meerdere kleinere databestanden in de tempdb te hebben, dan één grote
- Tot SQL Server 2014 kan het aanzetten van trace flag 1118 een significante verbetering in de performance betekeken. Trace flag 1118 verlicht de druk op de zogenoemde (S)GAM pagina’s, omdat alle enkelvoudige pagina toewijzingen worden uitgeschakeld. Dit gedrag is standaard vanaf SQL Server 2016; trace flag 1118 hoeft op deze versie en hoger niet te worden aangezet.
- Zet de databestanden en logbestanden van de tempdb bij voorkeur op een aparte fysieke schijf; niet zijnde de C-schijf
- Zorg voor een ruime autogrowth (in plaats van de standaard 64Mb die Microsoft gebruikt)
- Monitor de groei van de tempdb
Gebruikte bronnen vanuit Microsoft:
Microsoft Docs: tempdb database
Support Microsoft: Recommendation to reduce allocation contention
Micorsoft Docs: Working with tempdb in SQL Server 2005
Foutmelding in kubusverwerking via een SQL Agent Job
UItgangspunt
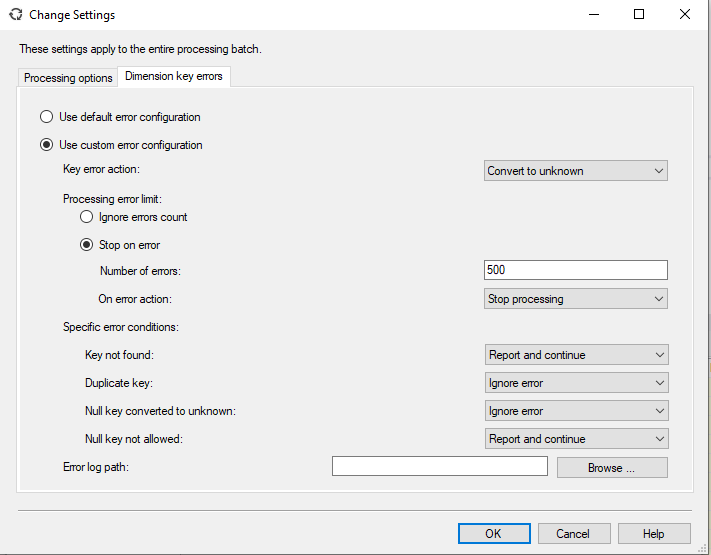
Er is een kubusdatabase waarbij meetwaarden worden gevonden die een onbekende dimensiewaarde hebben. Om te voorkomen dat dit een foutmelding tijdens het bijwerken van de data (process database) plaatsvindt, worden in het tabblad “Dimension key errors” binnen Batch Settings Summary gewijzigd. Daarbij worden de volgende keuzes gemaakt:
– Bij fouten in dimensies worde de waarde naar ‘unknown’ geconverteerd
– Er worden in totaal maximaal 500 dimensiefouten geaccepteerd
– Wanneer de dimensiewaardie niet wordt gevonden, gaat het bijwerken van de kubus door
– Wanneer een niet toegestane Null key wordt gevonden, gaat het bijwerken ook door
Grafisch:
Wanneer de kubus op deze wijze via een SQL Agent job wordt bijgewerkt (process database) zal de SQL Agent job met de volgende melding falen:
<Warning WarningCode=”1092354050″ Description=”Server: Operation completed with … problems logged.” … />
De SQL Agent job geeft dus een harde foutmelding. Wees er dus op bedacht dat het aantal en soort fouten bij het instellen van de kubusverversing zijn geaccepteerd en dat de SQL Agent job daarmee eigenlijk onterecht faalt.
Omdat de SQL Agent een onterechte fout geeft, is er een stukje maatwerkcode nodig om de jobs periodiek op juistheid en volledigheid te controleren. Onderstaand T-SQL kan hiervoor worden gebruikt. U zult zelf even moeten kijken welke velden uit deze tabellen bruikbaar voor u zijn.
SELECT * FROM msdb.dbo.sysjobs j INNER JOIN msdb.dbo.sysjobsteps s ON j.job_id = s.job_id INNER JOIN msdb.dbo.sysjobhistory h ON s.job_id = h.job_id AND s.step_id = h.step_id
SQL Server 2019 bug in logshipping
Bij het opzetten van logshipomgevingen in SQL Server 2019 werd mijn aandacht gevraagd voor een vrij bijzondere foutmelding in de geschiedenis van de LSBackup, LSCopy en LSRestore jobs. De foutmelding was:
DateTime *** Error: Failed to convert parameter value from a SqlGuid to a String.(System.Data)
DateTime *** Error: Object must implement IConvertible.(mscorlib) ***
Dit is een bekende bug bij Microsoft die in Cumulative Update 2 is opgelost.
Probleem is beschreven in deze link: https://support.microsoft.com/en-us/help/4537869/fix-log-shipping-agent-is-not-able-to-log-history-and-error-informatio
Cumulative update 2 voor SQL Server 2019 is op 13 februari 2020 via deze kaartbak item gereleased: https://support.microsoft.com/en-us/help/4536075/cumulative-update-2-for-sql-server-2019
SQL Server foutmelding “String or binary data would be truncated” met trace flag 460 analyseren
Wellicht dat u de foutmelding herkent. Met deze foutmelding begint de eindeloze zoektocht naar het juiste veld en record waar dit probleem zich in voordoet.
Eindelijk heeft Microsoft een oplossing hiervoor gemaakt, te weten trace flag 460. Wanneer deze trace flag wordt aangezet, geeft SQL Server meer informatie over de foutmelding, namelijk het veld waar het probleem zich voordoet en het gevonden record.
Ik verwacht dat ontwikkelaars hier de nodige tijd mee zullen besparen. Deze trace flag is beschikbaar in SQL Server 2016 SP2, CU6 en SQL Server 2017, CU12
Meer informatie in deze link van Microsoft: https://support.microsoft.com/en-us/help/4468101/optional-replacement-for-string-or-binary-data-would-be-truncated. Voorbeelden in het Engels zijn beschikbaar via Brent Ozar: https://www.brentozar.com/archive/2019/03/how-to-fix-the-error-string-or-binary-data-would-be-truncated/.
SQL Server Database in Recovery Pending
Vandaag vond ik één van mijn SQL Server testdatabases in status recovery pending. In deze bijdrage een korte weergave van mijn analyse, bevindingen en acties
Wanneer zich een incident op de SQL Server niveau voordoet, is het altijd een goed idee om in de SQL Server logfile te kijken, wat er is gebeurd, wanneer dat is gebeurd en onder welke omstandigheden iets is gebeurd.
Zo vond ik dat de foutmelding op deze database zich voordeed onder de omstandigheid dat de machine waarop SQL Server staat geïnstalleerd een herstart heeft gehad. SQL Server vermeldde in de log dat de betrokken database daarna niet beschikbaar was, omdat de database bestanden niet gevonden werden. Deze database bestanden staan voor deze testdatabase op een NAS, waar de machine op het moment van starten van SQL Server nog geen toegang toe had. Dan wordt dus duidelijk waar de foutmelding vandaan komt.
Ik heb vastgesteld dat de NAS wel weer beschikbaar was op de wijze zoals ik die had geconfigureerd. Ik heb de SQL Server services opnieuw gestart en het probleem was daarmee verholpen.
Lessons learnt: kijk bij incidenten altijd in de SQL Server logs.
T-SQL – SELECT TOP 100 vs SELECT TOP 101
SQL Server heeft een fijne manier van sorteren. Een SELECT TOP 100 wordt door SQL Server veel efficiënter gesorteerd dan een SELECT TOP 101+. In de StackOverflow database wordt dat duidelijk, wanneer de ‘Actual Query Plan’ wordt aangezet en onderstaande query’s worden uitgevoerd
SELECT TOP 100 * FROM dbo.Users ORDER BY Reputation DESC GO SELECT TOP 101 * FROM dbo.Users ORDER BY Reputation DESC GO
Het verschil in aanpak door SQL Server wordt duidelijk door te kijken naar de memory grant.
Uw MS SQL Server database op een NAS?
Wellicht dat u dit herkent: u heeft een ontwikkeldatabase waar op uw servers geen ruimte meer voor is, maar u heeft nog wel een NAS staan met een hoop opslag beschikbaar. Het probleem: uw Microsoft SQL Server herkent de UNC adressen van de NAS niet en kan er niet goed mee om gaan. De oplossing: gebruik iSCSI. iSCSI zorgt ervoor dat (een deel van) uw NAS direct aan uw computer kan worden gekoppeld, daar een drive letter krijgt en door uw computer kan worden beheerd/benaderd. SQLTeam.NL beschikt over een Synology DS918+. Op de website van Synology wordt uitgelegd hoe op een Synology NAS een iSCSI Target-service kan worden aangemaakt en hoe deze op uw computer bekend wordt gemaakt.
Het spreekt voor zich dat deze oplossing alleen voor ontwikkel- en testdatabases is bedoeld. Het draaien van database oplossingen op een NAS is nu eenmaal langzamer.
Eén slecht query plan uit de cache van SQL Server verwijderen
De evolutie van een database administrator. Er komt een melding binnen: “Eén van de query’s is erg langzaam”.
- “We herstarten de machine”
- “We herstarten de SQL Server instance”
- “We herindexeren alle tabellen”
- “Laten we DBCC FREEPROCCACHE gebruiken”
- “Ja, laten we DBCC FREEPROCCACHE met beleid gebruiken”
Wacht! De functie DBCC FREEPROCCACHE met beleid gebruiken? Hoe dan?
Elke query die in de cache is opgeslagen, krijgt een unieke ‘identifier’. Die identifier wordt met de volgende query gevonden:
SELECT
cacheobjtype,
text,
plan_handle
FROM sys.dm_exec_cached_plans P
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE text NOT LIKE '%sys.dm_%'
De kolom text geeft de query terug en de kolom plan_handle geeft de unieke identifier terug. Met die identifier kan vervolgens alleen dat query plan uit de cache worden verwijderd met het commando:
DBCC FREEPROCCACHE (plan_handle)
Dus vanaf vandaag worden alleen nog maar slechte query plannen via de functie DBCC FREEPROCCACHE verwijderd.